|
| |
Evolution Cruncher Chapter 8 DNA AND PROTEIN
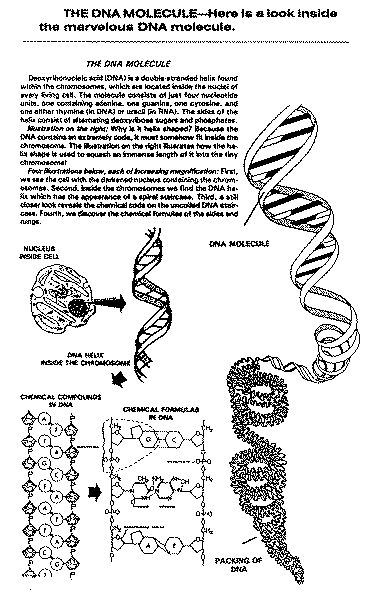
Why DNA and protein could not be produced by random chance This chapter is based on pp. 265-313 of Origin of the Life (Volume Two of our three-volume Evolution Disproved Series). Not included in this chapter are at least 110 statements by scientists. You will find them, plus much more, in the 3 Volume Encyclopedia on this site. One of the most important discoveries of the twentieth century was the discovery of the DNA molecule. It has had a powerful effect on biological research. It has also brought quandary and confusion to evolutionary scientists. If they cared to admit the full implications of DNA, it would also bring total destruction to their theory. This chapter goes hand in hand with the previous one. In the chapter on Primitive Environment, we learned that earthly surroundingsŚnow or earlierŚcould never permit the formation of living creatures from non-living materials. This present chapter will primarily discuss the DNA code, the components of proteinŚ and will show that each are so utterly complicated as to defy any possibility that they could have been produced by chance events. Yet random actions are the only kind of occurrences which evolutionists tell us have ever been used to accomplish the work of evolution. The significance of all this is immense. Because of the barrier of the multi-billion DNA code, not only was it impossible for life to form by accident, Śit could never thereafter evolve into new and different species! Each successive speciation change would require a totally new and differentŚbut highly exacting code to be in place on its very first day of its existence as a unique new species. As with a number of other chapters in this book, this one chapter alone is enough to completely annihilate evolutionary theory in regard to the origin or evolution of life. 1 - DNA AND ITS CODE GREGOR MENDELŚ(*#1/7 Gregor MendelÆs Monumental Discovery*) It was MendelÆs monumental work with genetics in the mid-19th century that laid the foundation for all modern research work in genetics. The complete story will be found on our website. YOUR BODYÆS BLUEPRINTŚ(*#2 The Story of DNA*) Each of us starts off as a tiny sphere no larger than a dot on this page. Within that microscopic ball there is over six feet of DNA (deoxyribonucleic acid), all coiled up. Inside that DNA is the entire code for what you will become,Śall your organs and all your features. The DNA itself is strung out within long coiling strips. DNA is the carrier of the inheritance code in living things. It is like a microscopic computer with a built-in memory. DNA stores a fantastic number of "blueprints," and at the right time and place issues orders for distant parts of the body to build its cells and structures. You have heard of "genes" and "chromosomes." Inside each cell in your body is a nucleus. Inside that nucleus are, among other complicated things, chromosomes. Inside the chromosomes are genes. The genes are attached to chromosomes like beads on a chain. Inside the genes is the complicated chemical structure we call DNA. Each gene has a thousand or more such DNA units within it. Inside each cell are tens of thousands of such genes, grouped into 23 pairs of chromosomes.
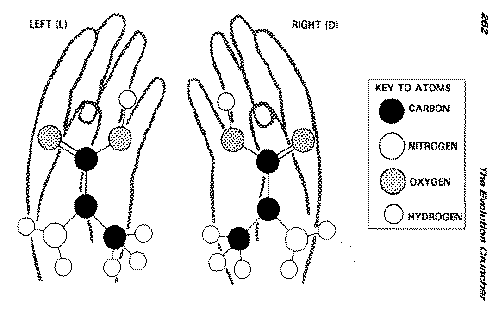
Inside the DNA is the total of all the genetic possibilities for a given species. This is called the gene pool of genetic traits. It is also called the genome. That is all the traits your species can have; in contrast, the specific sub-code for YOU is the genotype, which is the code for all the possible inherited features you could have. The genotype is the individualÆs code; the genome applies to populations; the entire species. (For clarification, it should be mentioned here that the genotype includes all the features you could possibly have in your body, but what you will actually have is called the phenotype. This is because there are many unexpressed or recessive characters in the genotype that do not show up in the phenotype. For example, you may have had both blue and brown eye color in your genotype from your ancestors, but your irises will normally only show one color.) COILED STRIPSŚ(*#3/33 The Origin of DNA*) Your own DNA is scattered all through your body in about 100 thousand billion specks, which is the average number of living cells in a human adult. What does this DNA look like? It has the appearance of two intertwined strips of vertical tape that are loosely coiled about each other. From bottom to top, horizontal rungs or stairs reach across from one tape strip to the other. Altogether, each DNA molecule is something like a spiral staircase. The spiraling sides in the DNA ladder are made of complicated sugar and phosphate compounds, and the crosspieces are nitrogen compounds. It is the arrangement of the chemical sequence in the DNA that contains the needed information. The code within each DNA cell is complicated in the extreme! If you were to put all the coded DNA instructions from just ONE single human cell into English, it would fill many large volumes, each volume the size of an unabridged dictionary! DOUBLE-STRANDED HELIXŚDeoxyribonucleic acid (DNA) is a double-stranded helix found within the chromosomes, which are located inside the nuclei of every living cell. The molecule consists of just four nucleotide units, one containing adenine, one guanine, one cytosine, and one either thymine (in DNA) or uracil (in RNA). The sides of the helix consist of alternating deoxyribose sugars and phosphates. The illustration shows the strange shape of DNA. It has that shape because it must fit inside the chromosome. It does this by squashing an immense length into the tiny chromosome. It could not do this if it did not have a twisted shape. The four illustrations show progressively smaller views of a DNA molecule and what is in it. DIVIDING DNAŚDNA has a very special way of dividing and combining. The ladder literally "unhooks" and "rehooks." When cells divide, the DNA ladder splits down the middle. There are then two single vertical strands, each with half of the rungs. Both now duplicate themselves instantlyŚand there are now two complete ladders, where a moment before there was but one! Each new strip has exactly the same sequence that the original strip of DNA had. This process of division can occur at the amazing rate of 1000 base pairs per second! If DNA did not divide this quickly, it could take 10,000 years for you to grow from that first cell to a newborn infant. Human cells can divide more than 50 times before dying. When they do die, they are immediately replaced. Every minute 3 billion cells die in your body and are immediately replaced. THE BASE CODEŚ(*#7 Coding in the Information*) The human body has about 100 trillion cells. In the nucleus of each cell are 46 chromosomes. In the chromosomes of each cell are about 10 billion of those DNA ladders. Scientists call each spiral ladder a DNA molecule; they also call them base pairs. It is the sequence of chemicals within these base pairs that provides the instructional code for your body. That instructional code oversees all your heredity and many of your metabolic processes. Without your DNA, you could not live. Without its own DNA, nothing else on earth could live. Within each DNA base pair is a most fantastic information file. A-T-C-T-G-G-G-T-C-T-A-AT-A, and on and on, is the code for one creature. T-G-C-T-C-A-A-G-A-G-T-G-C-C, and on and on, will begin the code for another. Each code continues on for millions of "letter" units. Each unit is made of a special chemical. The DNA molecule is shaped like a coiled ladder, which the scientists describe as being in the shape of a "double-stranded helix." Using data from a woman researcher (which they did not acknowledge), *Watson and *Crick "discovered" the structure of DNA. UTTER COMPLEXITYŚIn order to form a protein, the DNA molecule has to direct the placement of amino acids in a certain specific order in a molecule made up of hundreds of thousands of units. For each position, it must choose the correct amino acid from some twenty different amino acids. DNA itself is made up of only four different building blocks (A, G, C, and T). These are arranged in basic code units of three factors per unit (A-C-C, G-T-A, etc.). This provides 64 basic code units. With them, millions of separate codes can be sequentially constructed. Each code determines one of the many millions of factors in your body, organs, brain, and all their functions. If just one code were omitted, you would be in serious trouble. AN ASTOUNDING CLAIMŚThe evolutionists applied their theory to the amazing discoveries about DNAŚand came up with a totally astonishing claim: All the complicated DNA in each life-form, and all the DNA in every other life-formŚmade itself out of dirty water back in the beginning! There was some gravel around, along with some dirt. Nearby was some water, and overhead a lightning storm. The lightning hit the dirty water and made living creatures complete with DNA. They not only had their complete genetic code, but they were also immediately able to eat, digest food, move about, perform enzymatic and glandular functions, and all the rest. Instantly, they automatically knew how to produce additional cells, and their DNA began dividing (cells must continually replenish themselves or the creature quickly dies), their cells began making new ones, and every new cell could immediately do the myriad of functions that the first creature, an amoeba, can and must do. That same stroke of lightning made both a male and a female pair and their complete digestive, respiratory, and circulatory organs. It provided them with complete ability to produce offspring and they in turn more offspring. That same stroke of lightning also made their food, with all its own DNA, male and female pairs, etc., etc. And that, according to this childrenÆs story, is where we all came from! But it is a story that only very little children would find believable. "Laboratory experiments show that the basic building blocks of life, the proteins and organic molecules, form pretty easily in environments that have both carbon and water."Ś*Star Date Radio Broadcast, January 24, 1990. In this chapter we will not consider most of the above points. Instead we will primarily focus on the DNA and protein in each cell within each living creature. TRANSLATION PACKAGE NEEDED AT BEGINNINGŚThe amount of information in the genetic code is so vast that it would be impossible to put together by chance. But, in addition, there must be a means of translating it so the tissues can use the code. "Did the code and the means of translating it appear simultaneously in evolution? It seems almost incredible that any such coincidences could have occurred, given the extraordinary complexities of both sides and the requirement that they be coordinated accurately for survival. By a pre-Darwinian (or a skeptic of evolution after Darwin) this puzzle surely would have been interpreted as the most powerful sort of evidence for special creation."Ś*C. Haskins, "Advances and Challenges in Science" in American Scientist 59 (1971), pp. 298. Not only did the DNA have to originate itself by random accident, but the translation machinery already had to be produced by accidentŚand also immediately! Without it, the information in the DNA could not be applied to the tissues. Instant death would be the result. "The code is meaningless unless translated. The modern cellÆs translation machinery consists of at least fifty macromolecular components which are themselves encoded in DNA [!]; the code cannot be translated otherwise than by products of translation. It is the modern expression of omne vivum ex ovo [æevery living thing comes from an eggÆ]. When and how did this circle become closed? It is exceedingly difficult to imagine."Ś*J, Monod, Chance and Necessity (1971), p. 143. This translation package has also been termed an "adapter function." Without a translator, the highly complex coding contained within the DNA molecule would be useless to the organism. "The information content of amino acid sequences cannot increase until a genetic code with an adapter function has appeared. Nothing which even vaguely resembles a code exists in the physio-chemical world. One must conclude that no valid scientific explanation of the origin of life exists at present."Ś*H. Yockey, "Self Organization Origin of Life Scenarios and Information Theory," in Journal of Theoretical Biology 91 (1981), p. 13. "Cells and organisms are also informed [intelligently designed and operated] life-support systems. The basic component of any informed system is its plan. Here, argues the creationist, an impenetrable circle excludes the evolutionist. Any attempt to form a model or theory of the evolution of the genetic code is futile because that code is without function unless, and until, it is translated, i.e., unless it leads to the synthesis of proteins. But the machinery by which the cell translates the code consists of about seventy components which are themselves the product of the code."Ś*Michael Pitman, Adam and Evolution (1984), p. 147 [emphasis his]. DESIGNING CODESŚ*Sir Arthur Keith, a prominent anatomist of the 1930s (and co-producer of the Piltdown man hoax), said: "We do not believe in the theory of special creation because it is incredible." But life itself and all its functions and designs are incredible. And each true species has its own unique designs. A single living cell may contain one hundred thousand million atoms, but each atom will be arranged in a specific order. Yet all this is based on design, and design requires intelligenceŚin this case an extremely high order of intelligence. ManÆs most advanced thinking and planning has produced airplanes, rockets, personal computers, and flight paths around the moon. But none of this was done by accident. Careful thought and structuring was required. Design blueprints were carefully crafted into products. The biological world is packed with intricate, cooperative mechanisms that depend on encoded and detailed instructions for their development and interacting function. But complexity, and the coding it is based on, does not evolve. Left to themselves, all things become more random and disorganized. The more complex the system, the more elaborate the design needed to keep it operating and resisting the ever-pressing tendency to decay and deterioration. DNA and other substances like it are virtually unknown outside living cells. Astoundingly, they both produce cells and are products of cells; yet they are not found outside of cells. DNA is exclusively a product of the cell; we cannot manufacture it. The closest we can come to this is to synthesize simple, short chains of mononucleotide RNAŚand that is as far as we can go, in spite of all our boasted intelligence and million-dollar well-supplied, well-equipped laboratories. MESSENGER RNAŚSpecial "messenger RNA" molecules are needed. Without them, DNA is useless in the body. Consider the story of s-RNA: "The code in the gene (which is DNA, of course) is used to construct a messenger RNA molecule in which is encoded the message necessary to determine the specific amino acid sequence of the protein. "The cell must synthesize the sub-units (nucleotides) for the RNA (after first synthesizing the sub-units for each nucleotide, which include the individual bases and the ribose). The cell must synthesize the sub-units, or amino acids, which are eventually polymerized to form the protein. Each amino acid must be activated by an enzyme specific for that amino acid. Each amino acid is then combined with another type of RNA, known as soluble RNA or s-RNA. "There is a specific s-RNA for each individual amino acid. There is yet another type of RNA known as ribosomal RNA. Under the influence of the messenger RNA, the ribosomes are assembled into units known as polyribosomes. Under the direction of the message contained in the messenger RNA while it is in contact with polyribosomes, the amino acid-s-RNA complexes are used to form a protein. Other enzymes and key molecules are required for this. "During all of this, the complex energy-producing apparatus of the cell is used to furnish the energy required for the many syntheses."ŚDuane T. Gish, "DNA: Its History and Potential, "in W.E. Lemmerts (ed.), Scientific Studies in Special Creation (1971), p. 312. THE LIVING COMPUTERŚDNA and its related agencies operate dramatically like an advanced computer. "All this is strikingly similar to the situation in the living cell. For discs or tapes substitute DNA; for æwordsÆ substitute genes; and for æbitsÆ (a bit is an electronic representation of æyesÆ or ænoÆ) substitute the bases adenine, thymine, guanine and cytosine."Ś*Fred Hoyle and *C. Wickramasinghe, Evolution from Space (1981), p. 106. Everywhere we turn in the cell we find the most highly technical computerization. Electrical polarity is a key in the DNA. This is positive and negative electrical impulses, found both in the DNA and about the cell membrane, cytoplasm, and nucleus. The result is a binary system, similar to what we find in the most advanced computers in the world, but far more sophisticated and miniaturized. In computer science, a "byte" is composed of eight bits and can hold 256 different binary patterns, enough to equal most letters or symbols. A byte therefore stands for a letter or character. In biology the equivalent is three nucleotides called a codon. The biological code (within DNA) is based on these triplet patterns, as *Crick and *Brenner first discovered. This triad is used to decide which amino acid will be used for what purpose. THE BIOLOGICAL COMPILERŚThe code in both plants and animals is DNA, but DNA is chemically different than the amino acids, which it gives orders to make. This code also decides which of the 20 proteins the amino acids will then form themselves into. There is an intermediate substance between DNA and the amino acids and proteins. That mediating substance is t-DNA. But now the complexity gets worse: Each of the 20 proteins requires a different intermediate t-DNA! Each one works specifically to perform its one function; and chemically, each t-DNA molecule is unlike each of the other t-DNA molecules. The biological compiler that accomplishes these code tasks is t-DNA. It changes DNA code language into a different language that the cells can understandŚso they can set about producing the right amino acids and proteins. Without these many t-DNA molecules, the entire code and what it should produce would break down. DNA INDEXINGŚInformation that is inaccessible is useless, even though it may be very complete. Every computer requires a data bank. Without it, needed information cannot be retrieved and used. Large computer data banks have libraries of disc storage, but they require an index to use them. Without the index, the computer will not know where to look to find the needed information. DNA is a data bank of massive proportions, but indexes are also needed. These are different than the translators. There are non-DNA chemicals, which work as indexes to specifically locate needed information. The DNA and the indexes reciprocate; information is cycled round a feedback loop. The index triggers the production of materials by DNA. The presence of these materials, in turn, triggers indexing to additional productions. On a higher level of systems (nervous, muscular, hormonal, circulatory, etc.), additional indexes are to be found. The utter complication of all this is astounding. The next time you cut your finger, think of all the complex operations required for the body to patch it up. CELL SWITCHINGŚ"What is most important; what should be done next?" Computers function by following a sequential set of instructions. "First do this, and then do that," they are told, and in response they then switch from one subroutine to another. But how does the cell switch its DNA from one process to another? No one can figure this out. "In bacteria, for example, Jacob and Monod demonstrated a control system that operates by switching off ærepressorÆ molecules, i.e., unmasking DNA at the correct æline numberÆ to read off the correct (polypeptide) subroutines. With eukaryotes [a common type of bacteria], Britten and Davidson have tentatively suggested that æsensor genesÆ react to an incoming stimulus and cause the production of RNA. This, in turn, activates a æproducer gene,Æ m-RNA is synthesized and the required protein eventually assembled as a ribosome. Many DNA base sequences may thus be involved, not in protein or RNA production, but in control over that productionŚin switching the right sequences on or off at the right time."Ś*Michael Pitman, Adam and Evolution (1984), p. 124. THE FIVE CHEMICALS IN DNA AND RNAŚDNA is an extremely complex chemical molecule. Where did it come from? How did it form itself back in the beginning? How can it keep making copies of itself? There are two kinds of bases in the DNA code: purines (adenine and guanine) and pyrimidines (thymine or, in RNA, uracil; and cytosine). Where did these five chemicals come from? Charlie, you never told us the origin of the species; now help us figure out the origin of DNA! Do you desire fame and fortune? If you want a Nobel prize, figure out how to synthesize all five DNA chemicals. If you want a major place in history, figure out how to make living, functioning DNA. If sand and seawater did it, our highly trained scientists ought to be able to do it too. Scientists eventually devised complicated ways in expensive laboratories to synthesize dead compounds of four of these five, using rare materials such as hydrogen cyanide or cyanoacetylene. (Thymine remains unsynthesizable.) Sugar can be made in the laboratory, but the phosphate group is extremely difficult. In the presence of calcium ions, found in abundance in oceans and rivers, the phosphate ion is precipitated out. In life-forms enzymes catalyze the task, but how could enzymatic action occur outside of plants or animals? It would not happen. Then there are the polynucleotide strands that have to be formed in exactly the fit needed to neatly wrap about the DNA helix molecule. A 100 percent exact fit is required. But chemists seem unable to produce much in the way of synthesized polynucleotides, and they are totally unable to make them in predetermined sizes and shapes (*D. Watts, "Chemistry and the Origin of Life," in Life on Earth, Vol. 4, 1980, p. 21). If university-trained scientists, working in multimillion-dollar equipped and stocked laboratories, cannot make DNA and RNA, how can random action of sand and dirty water produce it in the beginning? NON-RANDOM: ONLY FROM INTELLIGENCEŚNon-random information is what is found in the genetic code. But such information is a proof that the code came from an intelligent Mind. Those searching for evidence of life in outer space have been instructed to watch for non-random signals as the best evidence that intelligent people live out there. Ponnamperuma says that such a "non-random pattern" would demonstrate intelligent extraterrestrial origin (*C. Ponnamperuma, The Origins of Life, 1972, p. 195). *CarI Sagan adds that a message with high information content would be "an unambiguously artificial [intelligently produced] interstellar message" (*Carl Sagan, Cosmos, 1980, p. 314). "To involve purpose is in the eyes of biologists the ultimate scientific sin . . The revulsion which biologists feel to the thought that purpose might have a place in the structure of biology is therefore revulsion to the concept that biology might have a connection to an intelligence higher than our own."Ś*Fred Hoyle and *Chandra Wickramasinghe, Evolution from Space (1981), p. 32. EACH CHARACTERISTIC CONTROLLED BY MANY GENESŚThe more the scientists have studied genetics, the worse the situation becomes. Instead of each gene controlling many different factors in the body, geneticists have discovered that many different genes control each factor! Because of this, it would thus be impossible for the basic DNA code to gradually "evolve." The underlying DNA code had to be there "all at once"; and once in place, that code could never change! "However it gradually emerged that most characters, even simple ones, are regulated by many genes: for instance, fourteen genes affect eye color in Drosophila. (Not only that. The mutation which suppresses æpurple eyeÆ enhances æhairy wing,Æ for instance. The mechanism is not understood.) Worse still, a single gene may influence several different characters. This was particularly bad news for the selectionists, of course . . In 1966 Henry Harris of London University demonstrated, to everyoneÆs surprise, that as much as 30 per cent of all characters are polymorphic [that is, each character controlled several different factors instead of merely one]. It seemed unbelievable, but his work was soon confirmed by Richard Lewontin and others."Ś*G.R. Taylor, Great Evolution Mystery (1983), pp. 165-166. (A clarification is needed here about the basic DNA code in a true species which never changes: Chapter 11, Animal and Plant Species, will explain how the DNA gene pool within a given true species can be broad enough to produce hybrids or varieties. This is why there are so many different types of dogs or why some birds, when isolated on an islandŚsuch as DarwinÆs finches on the Galapagos,Ścan produce bills of different length. This is why there are two shades of peppered moth and various resistant forms of bacteria.) In order to make the evolutionary theory succeed, the total organic complexity of an entire species somehow had to be invented long ago by chance,Śand it had to do it fast, too fastŚwithin seconds, or the creature would immediately die! 2 - MATHEMATICAL POSSIBILITIES OF DNA SCIENTIFIC NOTATIONŚThis is a number plus a small superscript numeral. Using it, small numbers can be written to denote numbers that are so immense that they are both incomprehensible and can only with difficulty be written out. Thus, 8 trillion (8,000,000,000,000) would be written 8 x 1012, and 1 billion (1,000,000,000) would be written simply as 109. Here are a few comparisons to show you the impossible large size of such numbers: Hairs on an average head 2 x 106 Seconds in a year 3 x 107 Retirement age (0 to 65) in seconds 2 x l09 World population 5 x 109 Miles [1.6 km] in a light-year 6 x 1010 Sand grains on all shores 1022 Observed stars 1022 Water drops in all the oceans 1026 Candle power of the sun 3 x 1027 Electrons in the universe 1080 It is said that any number larger than 2 x 1030 cannot occur in nature. In the remainder of this chapter, we will look at some immense numbers! MATH LOOKS AT DNAŚ(*#4/37 More Mathematical Impossibilities*) In the world of living organisms, there can be no life or growth without DNA. What are the mathematical possibilities (in mathematics, they are called probabilities) of JUST ONE DNA molecule having formed itself by the chance? "Now we know that the cell itself is far more complex than we had imagined. It includes thousands of functioning enzymes, each one of them a complex machine itself. Furthermore, each enzyme comes into being in response to a gene, a strand of DNA. The information content of the gene in its complexity must be as great as that of the enzyme it controls. "A medium protein might include about 300 amino acids. The DNA gene controlling this would have about 1000 nucleotides in its chain. Since there are four kinds of nucleotides in a DNA chain, one consisting of 1000 links could exist in 41000 different forms. "Using a little algebra (logarithms) we can see that 41000 is equivalent to 10600. Ten multiplied by itself 600 times gives the figure 1 followed by 600 zeros! This number is completely beyond our comprehension."Ś*Frank Salisbury, "Doubts about the Modern Synthetic Theory of Evolution," American Biology Teacher, September 1971, pp. 336-338. So the number of possible code combinations for an average DNA molecule is the numeral 4 followed by 1000 zeros! That is not 4000 (4 followed by 3 zeros), but 4 followed by a thousand zeros! How could random action produce the right combination out of that many possibilities for error? LIFE REQUIREDŚIn addition to DNA, many other materials, such as proteins, enzymes, carbohydrates, fats, etc, would have to be instantly made at the same time. The beating heart, the functioning kidneys, the circulatory vessels, etc. They would all need to be arranged within the complicated structure of an organism,Śand then they would have to be endued with LIFE! Without LIFE, none of the raw materials, even though arranged in proper order, would be worth anything. One does not extract life from pebbles, dirt, water, or a lightning bolt. Lightning destroys life; it does not make it. GOLEYÆS MACHINEŚA communications engineer tried to figure out the odds for bringing a non-living organism with few parts (only 1500) up to the point of being able to reproduce itself. "Suppose we wanted to build a machine capable of reaching into bins for all of its parts, and capable of assembling from those parts a second machine just like itself."Ś*Marcel J.E. Goley, "Reflections of a Communications Engineer," in Analytical Chemistry, June 1961, p. 23. Likening a living organism to a machine that merely reached out and selected parts needed to make a duplicate of itself, Goley tried to figure the odds for 1500 needed itemsŚrequiring 1500 right choices in a row. Many different parts would be needed, and Goley assumed they would all be lying around near that manufacturing machine! Goley assumes that its mechanical arm will have only a 50-50 chance of error in reaching out and grabbing the right piece! Such a ratio (1500 50.50 choices) is preposterous (it ought to be one chance in a hundred million for EACH of the correct 1500 selections from among 1500 items), but Goley then figures the odds based on such a one-in-two success rate of reaches. But even with such a high success rate, Goley discovered that there was only one chance in 10450 that the machine could succeed in reproducing itself! That is 1 followed by 450 zeros! Far smaller are all the words in all the books ever published. They would only amount to 1020, and that would be equivalent to only 66 of those 1500 50-50 choices all made correctly in succession! TOO MANY NUCLEOTIDESŚJust the number of nucleotides alone in DNA would be too many for GoleyÆs machine calculations. There are not 1500 parts to work out the probabilities onŚthere are multiplied thousands of factors, of which the nucleotides constitute one factor. (1) There are 5,375 nucleotides in the DNA of an extremely small bacterial virus (theta-x-174). (2) There are about 3 million nucleotides in a single cell bacteria. (3) There are more than 16,000 nucleotides in a human mitochondrial DNA molecule. (4) There are approximately 3 billion nucleotides in the DNA of a mammalian cell. (People and most animals are mammals.) Technically, a "nucleotide" is a complex chemical structure composed of a (nucleic acid) purine or pyrimidine, one sugar (usually ribose or deoxyribose), and a phosphoric group. Each one of those thousands of nucleotides within each DNA is aligned sequentially in a very specific order! Imagine 3 billion complicated chemical links, each of which has to be in a precisely correct sequence! NOT POSSIBLE BY CHANCEŚMany similar mathematical comparisons could be made. The point is that chance cannot produce what is in a living organism, Śnot now, not ever before, not ever in the future. It just cannot be done. And even if the task could be successfully completed, when it was done, that organism would still not be alive! Putting stuff together in the right combination does not produce life. And once made, it would have to have an ongoing source of water, air, and living food continually available as soon as it evolved into life. When the evolutionistÆs organism emerged from rock, water, and a stroke of lightning hitting it on the head,Śit would have to have its living food source made just as rapidly. The problems and hurdles are endless. "Based on probability factors . . any viable DNA strand having over 84 nucleotides cannot be the result of haphazard mutations. At that stage, the probabilities are 1 in 4.80 x 1050. Such a number, if written out, would read: 480,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000. "Mathematicians agree that any requisite number beyond 1050 has, statistically, a zero probability of occurrence (and even that gives it the æbenefit of the doubtÆ). Any species known to us, including æthe smallest single-cell bacteria, have enormously larger numbers of nucleotides than 100 or 1000. In fact, single cell bacteria display about 3,000,000 nucleotides, aligned in a very specific sequence. This means, that there is no mathematical probability whatever for any known species to have been the product of a random occurrenceŚrandom mutations (to use the evolutionistÆs favorite expression)."Ś*I.L. Cohen, Darwin was Wrong (1984), p. 205. Wysong explains the requirements needed to code one DNA molecule. By this he means selecting out the proper proteins, all of them left handed, and then placing them in their proper sequence in the moleculeŚand doing it all by chance: "This means 1/1089190 DNA molecules, on the average, must form to provide the one chance of forming the specific DNA sequence necessary to code the 124 proteins. 1089190 DNAs would weigh 1089147 times more than the earth, and would certainly be sufficient to fill the universe many times over. It is estimated that the total amount of DNA necessary to code 100 billion people could be contained in Į of an aspirin tablet. Surely 1089147 times the weight of the earth in DNAs is a stupendous amount and emphasizes how remote the chance is to form the one DNA molecule. A quantity of DNA this colossal could never have formed."ŚR.L. Wysong, The Creation-Evolution Controversy, p. 115. A GEM OF A QUOTATIONŚEvolutionists claim that everything impossible can happen by the most random of chances,Śsimply by citing a large enough probability number. *Peter Mora explains to his fellow scientists the truth about evolutionary theorizing: "A further aspect I should like to discuss is what I call the practice of avoiding the conclusion that the probability of a self-reproducing state is zero. This is what we must conclude from classical quantum mechanical principles, as Wigner demonstrated. "These escape clauses [the enormous chance-occurrence numbers cited as proof by evolutionists that it could be done] postulate an almost infinite amount of time and an almost infinite amount of material (monomers), so that even the most unlikely event could have happened. This is to invoke probability and statistical considerations when such considerations are meaningless. LEFT- AND RIGHT-HANDED AMINO ACID MOLECULE
"When for practical purposes the condition of infinite time and matter has to be invoked [in order to make evolution succeed], the concept of probability [possibility of its occurrence] is annulled. By such logic we can prove anything, such as that no matter how complex, everything will repeat itself, exactly and innumerably."Ś*P.T. Mora, "The Folly of Probability," in *S.W. Fox (ed.), The Origins of Prebiological Systems and of Their Molecular Matrices (1965), p. 45. 3 - AMINO ACIDS AND PROTEIN PROTEIN NEEDED ALSOŚ(*#6 Amino Acid Functions*) Now letÆs look at protein: Putting protein and DNA together will not make them alive; but, on the other hand, there can be no life without BOTH the protein and the DNA. Proteins would also have had to be made instantly, and in the right combination and quantity,Śat the very beginning. And do not forget the sequence: Protein has to be in its proper sequence, just as DNA has to be in its correct sequential pattern. Proteins come in their own complicated sequence! They have their own coding. That code is "spelled out" in a long, complicated string of materials. Each of the hundreds of different proteins is, in turn, composed of still smaller units called amino acids. There are twenty essential amino acids (plus two others not needed after adulthood in humans). The amino acids are complex assortments of specifically arranged chemicals. Making those amino acids out of nothing, and in the correct sequence,Śand doing it by chanceŚwould be just as impossible, mathematically, as a chance formation of the DNA code! ONLY THE LEFT-HANDED ONESŚWe mentioned, in chapter 6 (Inaccurate Dating Methods), the L and D amino acids. That factor is highly significant when considering the possibility that amino acids could make themselves by chance. Nineteen of the twenty amino acids (all except glycine) come in two forms: a "D" and an "L" version. The chemicals are the same, but are arranged differently for each. The difference is quite similar to your left hand as compared with your right hand. Both are the same, yet shaped opposite to each other. These two amino acid types are called enantiomers [en-anti-AWmers]. (Two other names for them are enantiomorphs and sterioisomers). (On the accompanying chart, note that they are alike chemically, but different dimensionally. Each one is a mirror image of the other. One is like a left-handed glove; the other like a right-handed one. A typical amino acid in both forms is illustrated.) For simplicityÆs sake, in this study we will call them the left-handed amino acid (the "L") and the right-handed amino acid (the "D"). Living creatures have to have protein, and protein is composed of involved mixtures of several of the 20 left amino acids. ŚAnd all those amino acids must be left-handed, not right-handed! (It should be mentioned that all sugars in DNA are right-handed.) (For purposes of simplification we will assume that right-handed amino acids never occur in living amino acids, but there are a few exceptions, such as in the cell walls of some bacteria, in some antibiotic compounds, and all sugars.) "Many researchers have attempted to find plausible natural conditions under which L-amino acids would preferentially accumulate over their D-counterparts, but all such attempts have failed. Until this crucial problem is solved, no one can say that we have found a naturalistic explanation for the origin of life. Instead, these isomer preferences point to biochemical creation."ŚDean H. Kenyon, affidavit presented to U.S. Supreme Court, No. 85-15, 13, in "Brief of Appellants," prepared under the direction of William J. Guste, Jr., Attorney General of the State of Louisiana, October 1985, p. A-23. TOTAL IGNORANCEŚ(*#5/29 DNA, Protein and the Cell*) Scientists have a fairly good idea of the multitude of chemical steps in putting together a DNA molecule; but, not only can DNA not be synthesized "by nature" at the seashore, highly trained technicians cannot do it in their million-dollar laboratories!
Dozens of inherent and related factors are involved. One of these is the gene-protein link. This had to occur before DNA could be usable, yet no one has any idea how it can be made now, much less how it could do it by itself in a mud puddle.
4 - SYNTHESIZED PROTEIN THE MILLER EXPERIMENTSŚIn 1953, a graduate biochemistry student (*Stanley Miller) sparked a non-oxygen mixture of gases for a week and produced some microscopic traces of non-living amino acids. We earlier discussed this in some detail in chapter 7, The Primitive Environment (which included a discription of the complicated apparatus he used), showing that *StanleyÆs experiment demonstrated that, if by any means amino acids could be produced, they would be a left-handed and right-handed mixtureŚand therefore unable to be used in living tissue.
Even if a spark could anciently have turned some chemicals into amino acids, the presence of the right-handed ones would clog the body machinery and kill any life-form they were in. (1) There are 20 amino acids. (2) There are 300 amino acids in a specialized sequence in each medium protein. (3) There are billions upon billions of possible combinations! (4) The right combination from among the 20 amino acids would have to be brought together in the right sequenceŚin order to make one useable protein properly. (5) In addition to this, the ultra-complicated DNA strands would have to be formed, along with complex enzymes, and more and more, and still more. IMPOSSIBLE ODDSŚWhat are the chances of accomplishing all the aboveŚand thus making a living creature out of protein manufactured by chance from dust, water, and sparks? Not one chance in billions. It cannot happen. Evolutionists speak of "probabilities" as though they were "possibilities," if given enough odds. But reality is different than their make-believe numbers. There are odds against your being able to throw a rock with your armŚand land it on the other side of the moon. The chances that you could do it are about as likely as this imagined animal of the evolutionists, which makes itself out of nothing and then evolves into everybody else. A mathematician would be able to figure the odds of doing it as a scientific notation with 50 or so zeros after it, but that does not mean that you could really throw a rock to the moon! Such odds are not really "probabilities," they are "impossibilities!" The chances of getting accidentally synthesized left amino acids for one small protein molecule is one chance in 10210. That is a number with 210 zeros after it! The number is so vast as to be totally out of the question. Here are some other big numbers to help you grasp the utter immensity of such gigantic numbers: Ten billion years is 1018 seconds. The earth weighs 1026 ounces. From one side to the other, the universe has a diameter of 1028 inches. There are 1080 elementary particles in the universe (subatomic particles: electrons, protons, neutrons, etc.). Compare those enormously large numbers with the inconceivably larger numbers required for a chance formulation of the right mixture of amino acids, proteins, and all the rest out of totally random chance combined with raw dirt, water, and so forth. How long would it take to walk across the 1028 inches from one side of the universe to the other side? Well, after you had done it, you would need to do it billions of times more before you would even have time to try all the possible chance combinations of putting together just ONE properly sequenced left-only amino acid protein in the right order. After *MillerÆs amino acid experiment, researchers later tried to synthesize proteins. The only way they could do it was with actual amino acids from living tissue! What had they accomplished? Nothing, absolutely nothing. But this mattered not to the media; soon newspaper headlines shouted, "SCIENTISTS MAKE PROTEIN!"
5 - MORE PROBLEMS WITH PROTEIN ALL 20 - BUT IN 39 FORMSŚThe evolutionists tell us that, at some time in the distant past, all the proteins made themselves out of random chemicals floating in the water or buried in the soil. But there are approximately 20 different essential amino acids. Each of them, with the exception of glycine, can exist in both the L (left-handed) and D (right-handed) structual forms. In living tissue, the L form is found; in laboratory synthesis, equal amounts of both the L and D forms are produced. There is no way to synthesize the L form by itself. TRYPTOPHAN SYNTHETASE AŚHere is the amino acid sequence of just one protein in your body. The amino acid units (written from left to right) are connected. If separated, they would read like this: methionyl, glutaminyl, arginyl, etc. TRYPTOPHAN SYNTHETASE A
Here are all 39 forms. What a hodgepodge for the random accidents of evolution to sort throughŚand come up with only the L forms. Each one has its own complicated sequence of amino acids: 1 - Glycine 2a - L-Alanine 2b - D-Alanine 3a - L-Valine 3b - D-Valine 4a - L-Leucine 4b - D-Leucine 5a - L-Isoleucine 5b - D-Isoleucine 6a - L-Serine 6b - D-Serine 7a - L-Threonine 7b - D-Threonine 8a - L-Cysteine 8b - D-Cysteine 9a - L-Cystine 9b - D-Cystine 10a - L-Methionine 10b - D-Methionine 11a - L-Glutamic Acid 11b - D-Glutamic Acid 12a - L-Aspartic Acid 12b - D-Aspartic Acid 13a - L-Lysine 13b - D-Lysine 14a - L-Arginine 14b - D-Arginine 15a - L-Histidine 15b - D-Histidine 16a - L-Phenylalanine 16b - D-Phenylalanine 17a - L-Tyrosine 17b - D-Tyrosine 18a - L-Tryptophan 18b - D-Tryptophan 19a - L-Proline 19b - D-Proline 20a - L-Hydroxyproline 20b - D-Hydroxyproline WHY ONLY THE L FORMŚYou might wonder why the D form of protein would not work equally well in humans and animals. The problem is that a single strand of protein, once it is constructed by other proteins (yes, the complicated structure of each protein is constructed in your body cells by other brainless proteins!), it immediately folds into a certain pattern. If there was even one right-handed amino acid in each lengthy string, it could not fold properly. (See our special study on Protein on our website. It is fabulous, and shows the astoundingly complex activities of proteins inside the cell.) 6 - ORIGINATING FIVE SPECIAL MATERIALS We are omitting this section from this paperback. It consists of detailed information on the step-by-step requirements needed to produce proteins, sugars, enzymes, fats, and DNA. The complexity of all this is fabulous. Over three large pages are required just to list the steps! You will find this on pp. 280-283 of Vol. 2 of the three-volume Evolution Disproved series set or on our internet site, evolution-facts.org. 7 - ADDITIONAL MATHEMATICAL IMPOSSIBILITIES ALL BY CHANCEŚEarlier in this chapter, we said that the possible combinations of DNA were the number 4 followed by a thousand zeros. That tells us about DNA combinations; what about protein combinations? The possible arrangements of the 20 different amino acids are 2,500,000,000,000,000,000. If evolutionary theory be true, every protein arrangement in a life-form had to be worked out by chance until it worked rightŚfirst one combination and then another until one was found that worked right. But by then the organism would have been long dead, if it ever had been alive! Once the chance arrangements had hit upon the right combination of amino acids for ONE proteinŚthe same formula would have to somehow be repeated for the other 19 proteins. And then it would somehow have to be correctly transmitted to offspring! THE STREAM OF LIFEŚThe primary protein in your red blood cells has 574 amino acids in it. Until that formula was first produced correctly by chance, and then always passed on correctly, your ancestors could not have lived a minute, much less survived and reproduced. You have billions upon billions upon billions of red blood cells ("RBCs," the scientists call them) in your body. This is what makes your blood red. Each red blood cell has about 280 million molecules of hemoglobin, and it would take about 1000 red blood cells to cover the period at the end of this sentence. (Hemoglobin is the iron-carrying protein material in RBCs, which carries oxygen from the lungs to the tissues, and carbon dioxide from the tissues to the lungs.) Both in complexity and in enormous quantity, your red blood cells are unusual. Several large books could be filled with facts about your red blood cells. MAKING PROTEIN BY CHANCEŚThe probability of forming 124 specifically sequenced proteins of 400 amino acids each by chance is 1 x 1O64489. THAT is a BIG number! If we put a thousand zeros on each page, it would take a 64-page booklet just to write the number! The probability of those 124 specifically sequenced proteins, consisting of 400 all-left-amino acids each, being formed by chance, if EVERY molecule in all the oceans of 1031 planet earths was an amino acid, and these kept linking up in sets of 124 proteins EVERY second for 10 billion years would be 1 x 1078436. And THAT is another BIG number! That is one followed by 78,436 zeros! As mentioned earlier, such "probabilities" are "impossibilities." They are fun for math games, but nothing more. They have nothing to do with reality. Yet such odds would have to be worked out in order to produce just 124 proteins! Without success in such odds as these, multiplied a million-fold, evolution would be totally impossible. Throughout this and the previous chapter, we have only discussed the basics at the bottom of the ladder of evolution. We have, as it were, only considered the first few instants of time. But what about all the development after that? More total impossibilities. ENZYMESŚ*Fred Hoyle wrote in New Scientist that 2000 different and very complex enzymes are required for a living organism to exist. And then he added that random shuffling processes could not form a single one of these in even 20 billion years! He then added this: "I donÆt know how long it is going to be before astronomers generally recognize that the arrangement of not even one among the many thousands of biopolyers [enzymes, proteins, hormones, etc.] on which life depends could have been arrived at by natural processes here on the earth. "Astronomers will have a little difficulty in understanding this because they will be assured by biologists that it is not so; the biologists having been assured in their turn by others that it is not so. The æothersÆ are a group of persons [the evolutionary theoreticians] who believe, quite openly, in mathematical miracles. "They advocate the belief that, tucked away in nature outside of normal physics, there is a law which performs miracles (provided the miracles are in the aid of biology). This curious situation sits oddly on a profession that for long has been dedicated to coming up with logical explanations . . The modern miracle workers are always found to be living in the twilight fringes of [the two laws of] thermodynamics."Ś*Fred Hoyle, "The Big Bang in Astronomy," in New Scientist, November 19, 1981, pp. 521-527. *Taylor says that proteins, DNA, and enzymesŚall of which are very complicatedŚwould all be required as soon as a new creature was made by evolution. "The fundamental objection to all these [evolutionary] theories is that they involve raising oneself by oneÆs own bootstraps. You cannot make proteins without DNA, but you cannot make DNA without enzymes, which are proteins. It is a chicken and egg situation. That a suitable enzyme should have cropped up by chance, even in a long period, is implausible, considering the complexity of such molecules. And there cannot have been a long time [in which to do it]."Ś*G.R. Taylor, Great Evolution Mystery (1983), p. 201. Enzyme systems do not work at all in the bodyŚuntil they are all there. "Dixon [a leading enzymologist] confesses that he cannot see how such a system could ever have originated spontaneously. The main difficulty is that an enzyme system does not work at all until it is complete, or nearly so. Another problem is the question of how enzymes appear without pre-existing enzymes to make them. æThe association between enzymes and life,Æ Dixon writes, æis so intimate that the problem of the origin of life itself is largely that of the origin of enzymes.Æ "Ś*Michael Pitman, Adam and Evolution (1984), pp. 144-145. DIXON-WEBB CALCULATIONŚIn 1964 *Malcolm Dixon and *Edwin Webb, on page 667 of their standard reference work, Enzymes, mentioned to fellow scientists that in order to get the needed amino acids in close enough proximity to form a single protein molecule, a total volume of amino-acid solution equal to 1050 times the volume of our earth would be needed! That would be 1 with 50 zeros after it multiplied by the contents of a mixing bowl. And the bowl would be so large that planet earth would be in it! After using the above method to obtain ONE protein molecule, what would it take to produce ONE hemoglobin (blood) molecule which contains 574 specifically coded amino acids? On page 279 of their Introduction to Protein Chemistry, *S.W. Fox and *J.F. Foster tell how to do it: First, large amounts of random amounts of all 20 basic types of protein molecules would be needed. In order to succeed at this, enough of the random protein molecules would be needed to fill a volume 10512 TIMES the volume of our entire known universe! And all of that space would be packed in solid with protein molecules. In addition, all of them would have to contain only left-handed amino acids (which only could occur 50 percent of the time in synthetic laboratory production). Then and only then could random chance produce just the right combination for ONE hemoglobin molecule, with the proper sequence of 574 left-handed amino acids! Yet there are also thousands of other types of protein molecules in every living cell, and even if all of them could be assembled by chance,Śthe cell would still not be alive. BEYOND DNA AND PROTEINŚWe have focused our attention on DNA and protein sequence in this chapter. Just for a moment, let us look beyond DNA and protein to a few of the more complicated organs in the human body. As we do so, the requirements which randomness would have to hurdle become truly fabulous. Consider the human brain, with its ten billion integrated cells in the cerebral cortex. How could all that come about by chance? Ask an expert on ductless glands to explain hormone production to you. Your head will swim. Gaze into the human eye and view how it is constructed, how it works. You who would cling to evolution as a theory that is workable give up! give up! There is no chance! Evolution is impossible! COMPUTER SIMULATIONŚPrior to the late 1940s, men had to work out their various evolutionary theories with paper and pencil. But then advanced computers were invented. This changed the whole picture. By the 1970s, it had become clear that the "long ages" theories just did not work out. Computer calculations have established the fact that, regardless of how much time was allotted for the task,Śevolution could not produce life-forms! Evolutionists can no longer glibly say, "Given enough time and given enough chance, living creatures could arise out of seawater and lightning, and pelicans could change themselves into elephants." (Unfortunately, evolutionists still say such things, because the ignorant public does not know the facts in this book.) But computer scientists can now feed all the factors into a large computerŚand get fairly rapid answers. Within a dramatically short time they can find out whether evolution is possible after all! Unfortunately, the evolutionists prefer to stay away from such computer simulations; they are afraid to face the facts. Instead they spend their time discussing their dreamy ideas with one another and writing articles about their theories in scientific journals. A computer scientist who spoke at a special biology symposium in Philadelphia in 1967, when computers were not as powerful as they are today, laid out the facts this way: "Nowadays computers are operating within a range which is not entirely incommensurate with that dealt with in actual evolution theories. If a species breeds once a year, the number of cycles in a million years is about the same as that which one would obtain in a ten-day computation which iterates a program whose duration is a hundredth of a second . . Now we have less excuse for explaining away difficulties [via evolutionary theory] by invoking the unobservable effect of astronomical [enormously large] numbers of small variations."Ś*M.P. Schutzenberger, Mathematical Challenges to the Neo-Darwinian Interpretation of Evolution (1967), pp. 73-75 (an address given at the Wistar Institute of Anatomy and Biology Symposium). *Schutzenberger than turned his attention to the key point that scientists admit to be the only real basis of evolution: gradual improvements in the genetic code through beneficial mutations, resulting in new and changed species: "We believe that it is not conceivable. In fact, if we try to simulate such a situation by making changes randomly at the typographic levelŚby letters or by blocks, the size of the unit need not matterŚon computer programs, we find that we have no chance (i.e., less than 1/101000) even to see what the modified program would compute; it just jams!Æ "Further, there is no chance (less than 1/101000) to see this mechanism (this single changed characteristic in the DNA) appear spontaneously and, if it did, even less [chance] for it to remain! "We believe that there is a considerable gap in the neo-Darwinian theory of evolution, and we believe this gap to be of such a nature that it cannot be bridged within the current conception of biology."Ś*Ibid. There is a one in 1/101000 chance that just one mutation could be beneficial and improve DNA. Now 1/101000is one with a thousand zeros after it! In contrast, one chance in a million only involves six zeros! Compare it with the almost impossible likelihood of your winning a major multimillion-dollar state lottery in the United States: That figure has been computed, and is only a relatively "tiny" number of six with six zeros after it. Evolution requires probabilities which are totally out of the realm of reality. THE DNA LANGUAGEŚAnother researcher, *M. Eden, in attendance at the same Wistar Institute, said that the code within the DNA molecule is actually in a structured form, like letters and words in a language. Like them, the DNA code is structured in a certain sequence, and only because of the sequence can the code have meaning. *Eden then goes on and explains that DNA, like other languages, cannot be tinkered with by random variational changes; if that is done, the result will always be confusion! "No currently existing formal language can tolerate random changes in the symbol sequences which express its sentences. Meaning is invariably destroyed."Ś*M. Eden, "Inadequacies of Neo-Darwinian Evolution as a Scientific Theory," in op. cit., p. 11. And yet evolutionary theory teaches that DNA and all life appeared by chance, and then evolved through random changes within the DNA! (For more information on those special evolutionary conferences, see chapter 1. History of Evolutionary Theory.) THE MORE TIME, THE LESS SUCCESSŚEvolutionists imagine that time could solve the problem: Given enough time, the impossible could become possible. But time works directly against success. Here is why: "Time is no help. Biomolecules outside a living system tend to degrade with time, not build up. In most cases, a few days is all they would last. Time decomposes complex systems. If a large æwordÆ (a protein) or even a paragraph is generated by chance, time will operate to degrade it. The more time you allow, the less chance there is that fragmentary æsenseÆ will survive the chemical maelstrom of matter."Ś*Michael Pitman, Adam and Evolution (1984), p. 233. ALL AT ONCEŚEverything had to come together all at once. Within a few minutes, all the various parts of the living organism had to make themselves out of sloshing, muddy water. "However, conventional Darwinian theory rationalizes most adaptations by assuming that sufficient time has transpired during evolution for natural selection to provide us with all the biological adaptations we see on earth today, but in reality the adaptive process must by necessity occur rather quickly (in one or at the most two breeding generations)."Ś*E. Steele, Somatic Selection and Adaptive Evolution (2nd ed. 1981), p. 3. "So the simultaneous formation of two or more molecules of any given enzyme purely by chance is fantastically improbable."Ś*W. Thorpe, "Reductionism in Biology," in Studies in the Philosophy of Biology (1974), p. 117. "From the probability standpoint, the ordering of the present environment into a single amino acid molecule would be utterly improbable in all the time and space available for the origin of terrestrial life."Ś*Homer Jacobson, "Information, Reproduction and the Origin of Life," American Scientist, January 1955, p. 125. "To form a polypeptide chain of a protein containing one hundred amino acids represents a choice of one out of 1O130 possibilities. Here again, there is no evidence suggesting that one sequence is more stable than another, energetically. The total number of hydrogen atoms in the universe is only 1078. That the probability of forming one of these polypeptide chains by change is unimaginably small; within the boundary of conditions of time and space we are considering it is effectively zero."Ś*E. Ambrose, The Nature and Origin of the Biological World (1982), p. 135. "Directions for the reproduction of plans, for energy and the extraction of parts from the current environment, for the growth sequence, and for the effector mechanism translating instruction into growthŚall had to be simultaneously present at that moment. This combination of events has seemed an incredibly unlikely happenstance, and has often been ascribed to divine intervention."Ś*Homer Jacobson, "Information, Reproduction and the Origin of Life," American Scientist, January 1955, p. 121. BACTERIA DISPROVE EVOLUTIONŚLet us go beyond DNA molecules and pieces of protein, and consider one of the simplest of life-forms. Scientists have studied in detail the bacterium, Escherichia coli. These bacteria are commonly found in the large bowel. Under favorable conditions bacterial cells can divide every 20 minutes. Then their offspring immediately begin reproducing. Theoretically, one cell can produce 1020 cells in one day! For over a century researchers have studied E-coli bacteria. All that time those bacteria have reproduced as much as people could in millions of years. Yet never has one bacterium been found to change into anything else. And those little creatures do not divide simply. The single chromosome replicates (makes a copy of itself), and then splits in two. Then each daughter cell splits in two, forming the various cells in the bacterium. These tiny bacteria can divide either sexually or asexually. Escherichia coli has about 5000 genes in its single chromosome strand. This is the equivalent of a million three-letter codons. Yet this tiny bacterium is one of the "simplest" living creatures that exists. Please, do not underestimate the complexity of this, a creature with only ONE chromosome: First, that one chromosome is a combination lock with a million units, arranged in a definite sequence. Second, each unit is made up of three sub-units (A-C-C, G-T-A, etc.). Third, the sub-units are combined from four different chemical building blocks: A, G, C, and T. What are the possible number of combinations for that one chromosome? Get a sheet of paper and figure that one out for yourself. FRAME SHIFTSŚThen scientists discovered an even "simpler" creature that lives in the human bowel. It is called the theta-x-174, and is a tiny virus. It is so small, that it does not contain enough DNA information to produce the proteins in its membrane! How then can it do it? How can it produce proteins without enough DNA code to produce proteins! Scientists were totally baffled upon making this discovery. Then they discovered the high-tech secret: The answer is but another example of a super-intelligent Creator. The researchers found that this tiny, mindless creature routinely codes for that protein thousands of times a dayŚand does it by "frame shift." To try to describe it in simple words, a gene is read off from the first DNA base to produce a protein. Then the same message is read againŚbut this time omitting the first base and starting with the second. This produces a different protein. And on and on it goes. Try writing messages in this manner, and you will begin to see how utterly complicated it is: "Try writing messages / writing messages in / messages in this / in this manner." That is how the simplest of viruses uses its DNA coding to make its protein! Does someone think that the virus was smart enough to figure out that complicated procedure with its own brains? Or will someone suggest that it all "just happened by chance?" With all this in mind, *Wally Gilbert, a Nobel prize winning molecular biologist, said that bacteria and viruses have a more complicated DNA code-reading system than the "higher forms of life." THE CENTRAL DOGMAŚ*Francis Crick, the co-discoverer of the structure of DNA, prepared a genetic principle which he entitled, "The Central Dogma": "The transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible."Ś*Francis Crick, "Central Dogma," quoted in *Richard Milner, Encyclopedia of Evolution (1990), p. 77. The Central Dogma is an important scientific principle and means this: The complex coding within the DNA in the cell nucleus decides the traits for the organism. But what is in the body and what happens to the body cannot affect the DNA coding. What this means is this: Species cannot change from one into another! All the members in a species (dogs, for example) can only be the outcome of the wide range of "gene pool" data in the DNA, but no member of that species can, because of the environment or what has happened to that individual, change into another species. Only changes in the DNA coding can produce such changes; nothing else can do it.
BLUE GENEŚAs we near press time on this paperback, announcement has been made that IBM has begun work on their largest computer to-date. It is called "Blue gene"; and it must be powerful, for they have been building ever larger supercomputers since the 1940s. This one will be 100 times more powerful than Big Blue, the computer used to defeat Kasperson in chess several years ago. They are trying to figure out something which is so utterly complicated that no lesser computer can handle the task. No, not something simple like computing a trip to Saturn and back. Their objective is solving something far more complicated. ŚIt is figuring out how a protein folds! In every cell in your body, brainless proteins assemble more proteins from amino acids. They put them into their proper sequence (!), and then, as soon as the task is ended, the new protein automatically folds down into a clump, as complicated as a piece of steel wool. IBM is trying to figure out the fold pattern instantly made by this microscopic piece of mindless, newborn protein! The computer will cost $100 million, and Stanford University is trying to get people to let them use their home computers to help with the task (go to standford.edu for details). They say they need the information to figure out drugs to counteract HIV and other viruses. So far, they can only get the protein to wiggle; they cannot get it to fold (NPR, Wednesday evening, September 27, 2000). As we go to press: It has recently been discovered that the terrible plague of Mad Cow Disease, (initially brought into existence by cannibalism) is caused by protiens that do not fold correctly. For more on proteins and how they do their work in the cell, go to our website, evolution-facts.org, and locate a special study on protein which we have prepared. It contains a remarkable collection of facts. EVOLUTION COULD NOT DO THISThe teeth of a rat are designed so the top two front teeth go behind the bottom two, at just the right angle to produce self-sharpening teeth. Engineers at General Electric wanted to design a self-sharpening saw blade in order to obtain exactly the right angle in relation to the metal it is cutting; so they studied the teeth of a rat. They found there was no other way it could be done as efficiently. As it slices through the metal, small pieces of the new blade are cut away by the metal, thus always keeping the blade sharp. That self-sharpening blade lasts six times longer than any other blade they had previously been able to make. All because the trained researchers studied the teeth of a rat. CHAPTER 8 - STUDY AND REVIEW QUESTIONSDNA AND PROTEIN GRADES 5 TO 12 ON A GRADUATED SCALE 1- Prepare a diagram of a DNA molecule. Use different colors to show the different parts. 2 - Research the story of how DNA was discovered and write a report on it. 3 - Would it be easier for DNA to be made by randomness or by researchers in a laboratory? Could living DNA be made in either place? 4 - Research into what is in a blood cell, and then write about the different parts. Underline those parts which could be produced by random action (called "natural selection"). 5 - There are 20 essential amino acids, 300 special-sequence amino acids in each medium-sized protein, and billions of possible sequences. What do you think would happen in your body if just one of those sequences was out of place? 6 - Can "non-random patterns" be produced randomly? Codes are made by intelligent people. Can they be produced by chance? 7 - Find out how DNA divides, and write a brief report on how it happens. 8 - Random production of amino acids always produce a 50-50 mixture of left- and right-handed forms of them. Could the randomness of evolution produce living tissue with only left-handed amino acids? 9 - Why is it that evolutionists do not give up trying to prove that impossible things can happen? 10 - There are 26 reasons why DNA cannot be originated outside of living tissue. List 10 which you consider to be the most unlikely to be accomplished synthetically. 11 - Briefly explain one of the following: translator package, messenger RNA, biological compiler, codon, nucleotide, t-DNA. 12 - Write a report on the mathematical possibilities (probabilities) that amino acids, protein, or DNA could be accidently produced by random activity in barrels of chemicals which filled all of space throughout the universe. You have just completed Chapter
8 DNA AND PROTEIN |